FLAIR
Artificial Intelligence challenges organised around geo-data and deep learning
Project maintained by IGNF
Bienvenue sur la page des datasets FLAIR de l'IGN!

| L'Institut national de l'information géographique et forestière (IGN) présente ses défis en matière d'IA et ses jeux de données de référence FLAIR (pour French Land cover from Aerospace ImageRy). Les jeux de données FLAIR mettent à disposition des données d'observation de la Terre provenant de différents capteurs aérospatiaux. Ces jeux de données couvrent de larges échelles et reflètent des cas réels et complexes de cartographie de l'occupation du sol. Nous nous engageons à soutenir la recherche et à favoriser l'innovation dans les domaines de l'observation de la Terre. Pour toute question concernant les données, leur accès et leur exploitation, ainsi que pour toute idée de futurs jeux de données ou suggestion de sujets, contactez nous à l'adresse suivante: flair@ign.fr |
|||
|---|---|---|---|
Explorez les jeux de données et les codes associés : |
|||
| Les jeux de données FLAIR sont sous la licence Licence Ouverte 2.0 d'Etalab. Faites mention de la paternité du jeu de données en citant le datapapers associé.  |
|||
 |
|||
 |
|||
FLAIR #1 : segmentation sémantique et adaptation de domaine 🌍🌱🏠🌳➡️🛩️
Challenge organisé par l'IGN avec le soutient de la SFPT.
Ce challenge s'est déroulé du 21 Novembre 2022 au 21 Mars 2023. Vous pouvez consulter les résultats ici.
FLAIR #1 datapaper 📑 : https://arxiv.org/pdf/2211.12979.pdf
FLAIR #1 dépôt github 📁 : https://github.com/IGNF/FLAIR-1-AI-Challenge
Modèles pré-entraînés : https://huggingface.co/collections/IGNF/flair-models-landcover-semantic-segmentation-65bb67415a5dbabc819a95de
▶️ Description du dataset (cliquer pour agrandir)
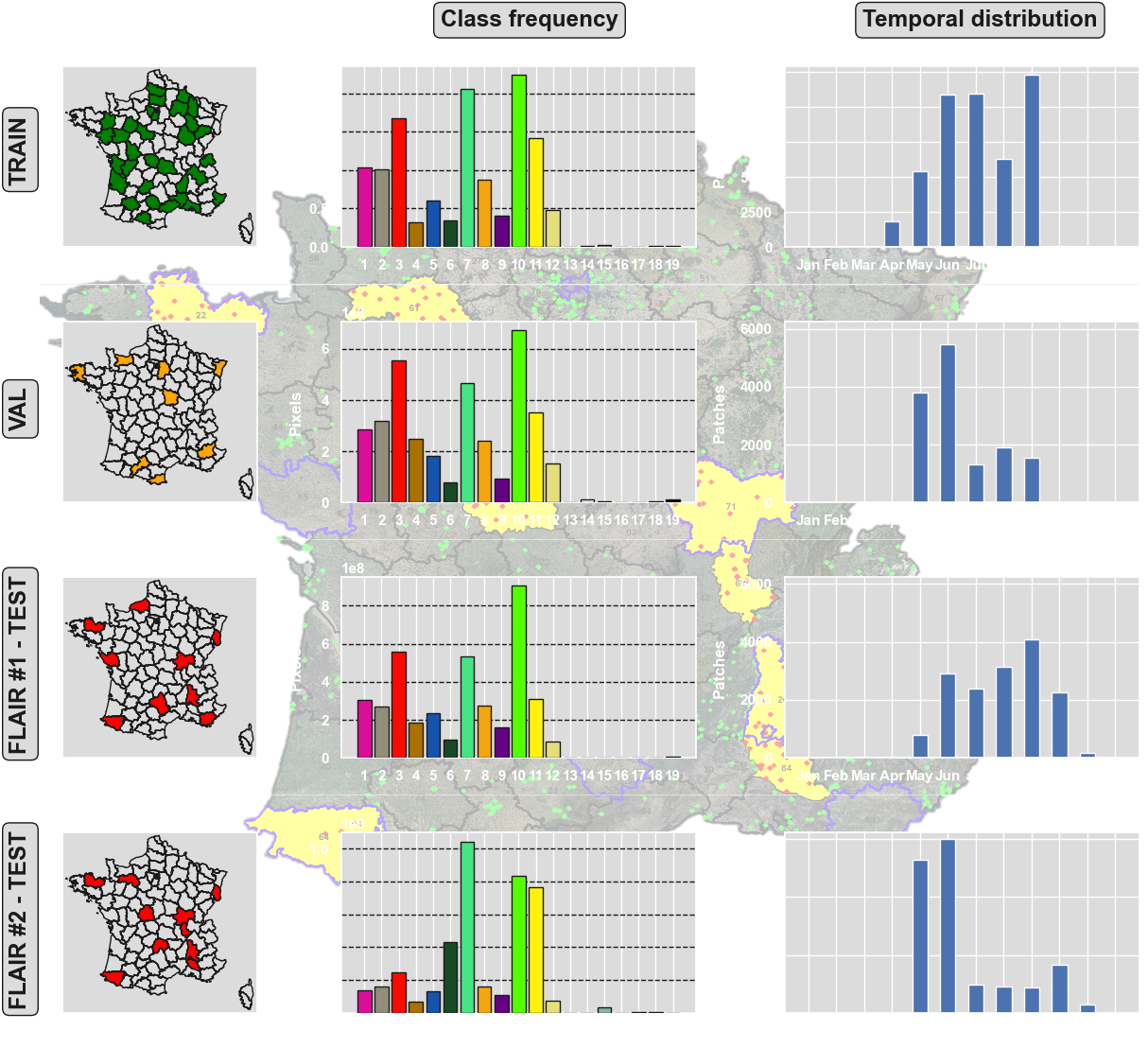
Avec des données acquises sur 50 départements et plus de 20 milliards de pixels annotés, ce jeu de données représente la diversité du territoire métropolitain, ses climats, ses écosystèmes et ses sols, dans le but de produire une cartographie à grande échelle. Différentes bases de données IGN (BD Ortho, RGE Alti) ainsi que des annotations produites manuellement par des experts photo-interprètes ont été assemblées pour permettre l’entraînement de modèles IA.
Les images aériennes de télédétection à l'échelle d'un pays sont nécessairement acquises à des dates et des heures différentes et dans des conditions différentes. De même, à grande échelle, les caractéristiques des classes sémantiques peuvent varier et devenir hétérogènes. Cela soulève des challenges pour la généralisation spatiale et temporelle des modèles d'apprentissage profond !
Le dataset FLAIR#1 est composé de 77,412 patches de 512x512 (résolution spatiale de 0.2m) avec une sémantique à 19 classes. Spécifiquement pour le challenge et les baselines associées et en raison d'une fréquence par classe déséquilibrée, la sémantique a été modifiée à 13 classes (>12 -> 13). Rapportez-vous au datapaper pour plus de précisions.
| Classe | Valeur | Freq.-entraînement (%) | Freq.-test (%) | |
|---|---|---|---|---|
| bâtiment | 1 | 8.14 | 8.6 | |
| zone perméable | 2 | 8.25 | 7.34 | |
| zone imperméable | 3 | 13.72 | 14.98 | |
| sol nu | 4 | 3.47 | 4.36 | |
| eau | 5 | 4.88 | 5.98 | |
| conifères | 6 | 2.74 | 2.39 | |
| feuillus | 7 | 15.38 | 13.91 | |
| brousaille | 8 | 6.95 | 6.91 | |
| vigne | 9 | 3.13 | 3.87 | |
| pelouse | 10 | 17.84 | 22.17 | |
| culture | 11 | 10.98 | 6.95 | |
| terre labourée | 12 | 3.88 | 2.25 | |
| piscine | 13 | 0.03 | 0.04 | |
| neige | 14 | 0.15 | - | |
| coupe | 15 | 0.15 | 0.01 | |
| mixte | 16 | 0.05 | - | |
| ligneux | 17 | 0.01 | 0.03 | |
| serres | 18 | 0.12 | 0.2 | |
| autre | 19 | 0.14 | - |
Le dataset couvre un total d'environ 812 km², avec des patches sélectionnés sur l'ensemble du territoire métropolitain afin de représenter sa diversité (domaines spatiaux). Les images aériennes incluent dans le dataset sont également acquisent à des mois et années différentes (domaines temporels).
 |
 |
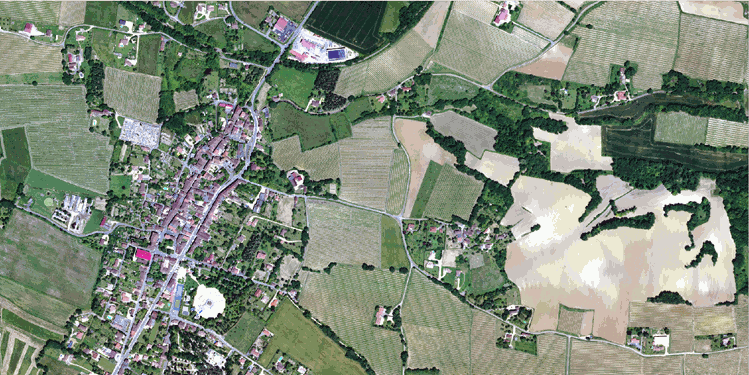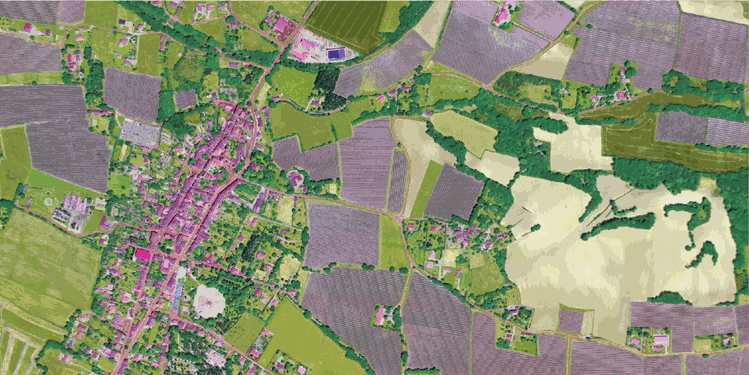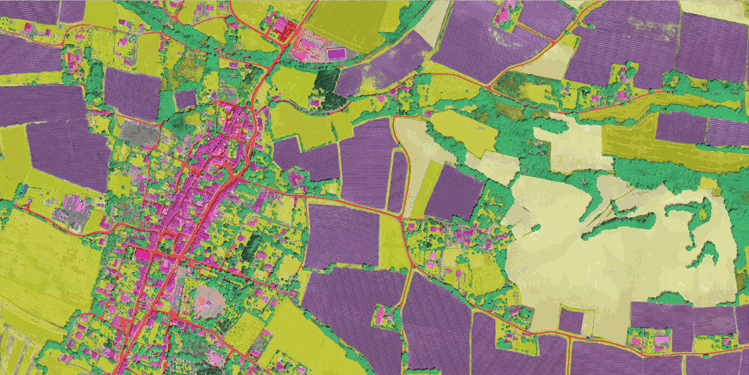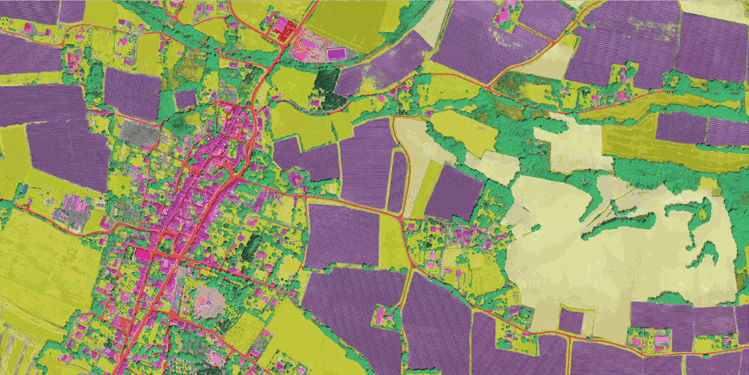
| Image aérienne ORTHO HR® | Annotations |
Le dataset de test contient 15,700 patches de 10 domaines spatiaux supplémentaires. La fréquence des classes et les domaines temporels sont également distinct du dataset d'entraînement, permettant d'analyser les capacités de généralisation et d'adaptation de domaines des méthodes développées.
▶️ Modèle de référence (baseline): U-Net (cliquer pour agrandir)
Une architecture U-Net avec un encodeur ResNet34 pré-entraîné de la librairie segmentation-models-pytorch a été utilisée pour les baselines. L'architecture utilisée permet l'intégration d'informations de métadonnées à l'échelle du patch et utilise des techniques d'augmentation des données d'image couramment utilisées. Les codes sont disponibles dans le dépôt FLAIR #1.
▶️ Téléchargement du dataset (cliquer pour agrandir)
| Données | Volume | Type | Lien |
|---|---|---|---|
| Images aériennes - entraînement | 50.7 Go | .zip | téléchargement |
| Images aériennes - test | 13.4 Go | .zip | téléchargement |
| Annotations - entraînement | 485 Mo | .zip | téléchargement |
| Annotations - test | 124 Mo | .zip | téléchargement |
| Métadonnées aériennes | 16.1 Mo | .json | téléchargement |
| Shapefile zones | 392 Ko | .gpkg | téléchargement |
| Jeu de données exemple (entraînement et test réduits) | 215 Mo | .zip | téléchargement |
Citation
Si vous utilisez des données de FLAIR #1, merci d'inclure la citation suivante:
Texte brut:
Anatol Garioud, Stéphane Peillet, Eva Bookjans, Sébastien Giordano, and Boris Wattrelos. 2022.
FLAIR #1: semantic segmentation and domain adaptation dataset. (2022).
DOI:https://doi.org/10.13140/RG.2.2.30183.73128/1
BibTex:
@article{ign2022flair1,
doi = {10.13140/RG.2.2.30183.73128/1},
url = {https://arxiv.org/pdf/2211.12979.pdf},
author = {Garioud, Anatol and Peillet, Stéphane and Bookjans, Eva and Giordano, Sébastien and Wattrelos, Boris},
title = {FLAIR #1: semantic segmentation and domain adaptation dataset},
publisher = {arXiv},
year = {2022}
}
FLAIR #2 : Information texturale et temporelle à partir d'imagerie optique multimodal pour la segmentation sémantique 🌍🌱🏠🌳➡️🛩️🛰️
Challenge organisé par l'IGN avec le soutient du CNES et de Connect by CNES dans le cadre d'un projet Copernicus / FPCUP.

FLAIR #2 datapaper 📑 : https://arxiv.org/pdf/2305.14467.pdf
FLAIR #2 NeurIPS datapaper 📑 : https://proceedings.neurips.cc/paper_files/paper/2023/file/353ca88f722cdd0c481b999428ae113a-Paper-Datasets_and_Benchmarks.pdf
FLAIR #2 NeurIPS poster 📑 : https://neurips.cc/media/PosterPDFs/NeurIPS%202023/73621.png?t=1699528363.252194
FLAIR #2 dépôt GitHub 📁 : https://github.com/IGNF/FLAIR-2-AI-Challenge
FLAIR #2 page du défi 💻 : https://codalab.lisn.upsaclay.fr/competitions/13447 [terminé]
{kind=link}
Modèles pré-entraînés : pour l'instant sur demande !
▶️ Contexte du challenge (cliquer pour agrandir)
Avec ce nouveau défi, les participants auront pour tâche de développer des solutions innovantes qui peuvent exploiter efficacement les informations texturales des images aériennes prises à une seule date, ainsi que les informations temporelles/spectrales provenant des séries temporelles des satellites Sentinel-2, afin d'améliorer la segmentation sémantique, l'adaptation de domaine et l'apprentissage par transfert. Vos solutions devraient relever les défis liés à la conciliation des différentes périodes d'acquisition, des résolutions spatiales différentes, de l'adaptation aux conditions d'acquisitions variables et de la gestion de l'hétérogénéité des classes sémantiques.
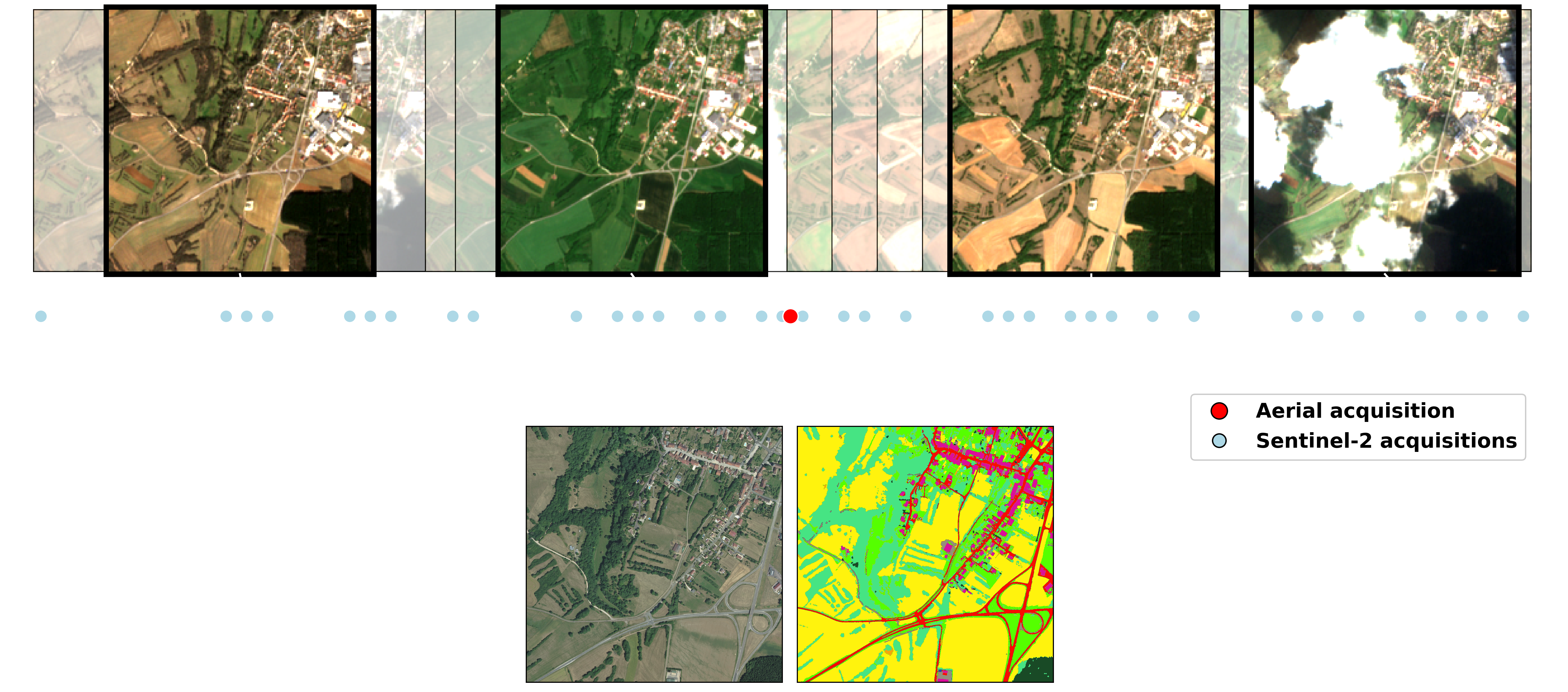
▶️ Description du dataset (cliquer pour agrandir)
Le jeu de données FLAIR #2 comprend 20,384,841,728 pixels annotés avec une résolution spatiale de 0,20 m à partir d'images aériennes, répartis en 77,762 patchs de taille 512x512. Le jeu de données FLAIR #2 inclut également une vaste collection de données satellites, avec un total de 51,244 acquisitions d'images des satellites Copernicus Sentinel-2. Pour chaque zone, les acquisitions sur un an ont été retenues, offrant des informations précieuses sur la dynamique spatio-temporelle et les caractéristiques spectrales de la couverture terrestre. En raison de la différence significative de résolution spatiale entre les images aériennes et les données satellites, les zones initialement définies manquent de contexte suffisant car elles ne sont composées que de quelques pixels Sentinel-2. Pour remédier à cela, une marge a été appliquée pour créer des zones plus grandes appelées super-zones. Cela garantit que chaque patch du jeu de données est associé à une super-zone de données Sentinel-2 de taille suffisante, offrant un niveau minimum de contexte provenant du satellite.
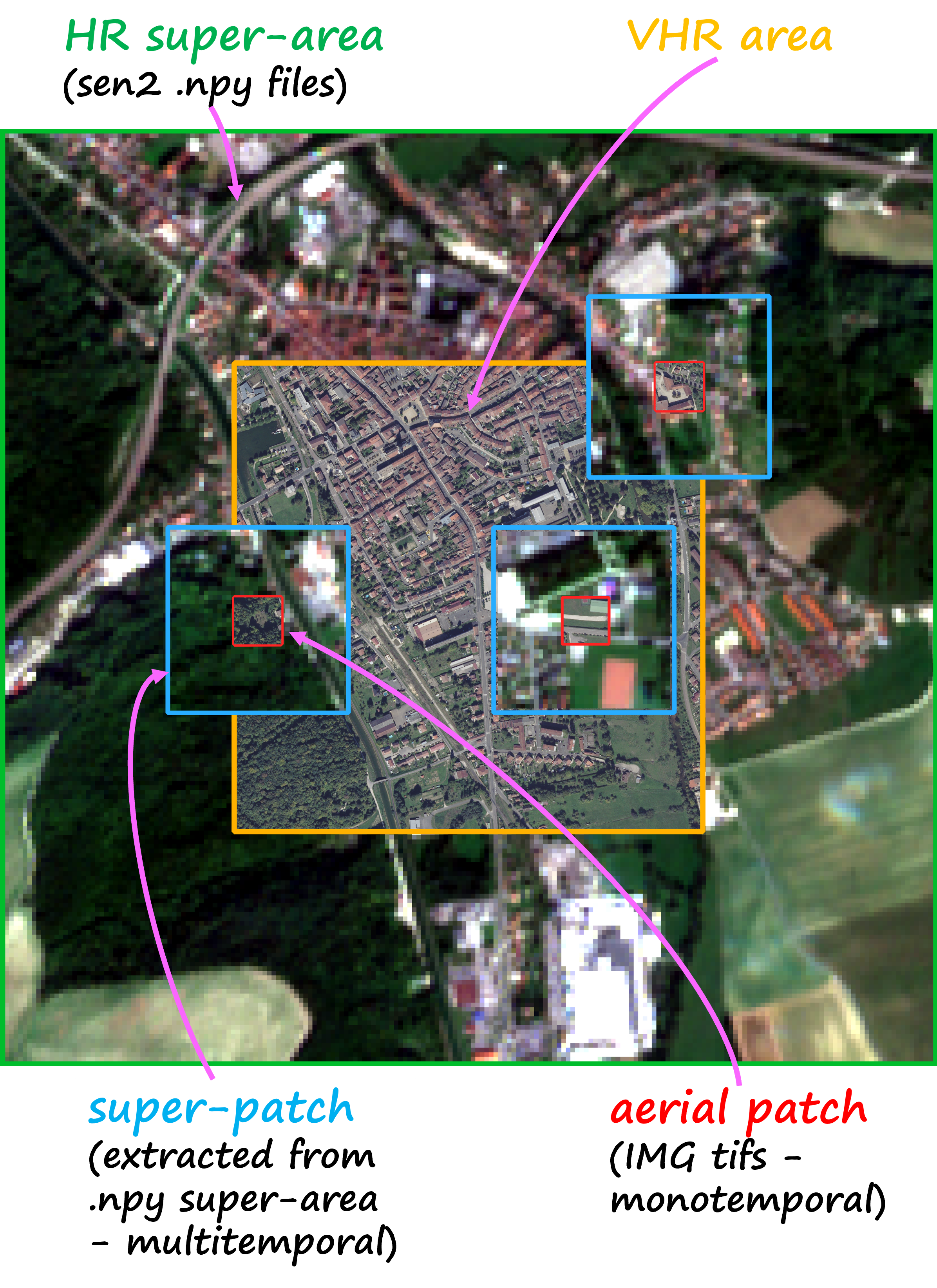
Le jeu de données couvre 50 domaines spatial, comprenant 916 zones réparties sur 817 km². Avec 13 classes sémantiques (plus 6 non utilisées dans ce défi), ce jeu de données constitue une base solide pour faire progresser les techniques de cartographie de la couverture du sol.
| Class | Value | Freq.-train (%) | Freq.-test (%) | |
|---|---|---|---|---|
| building | 1 | 8.14 | 3.26 | |
| pervious surface | 2 | 8.25 | 3.82 | |
| impervious surface | 3 | 13.72 | 5.87 | |
| bare soil | 4 | 3.47 | 1.6 | |
| water | 5 | 4.88 | 3.17 | |
| coniferous | 6 | 2.74 | 10.24 | |
| deciduous | 7 | 15.38 | 24.79 | |
| brushwood | 8 | 6.95 | 3.81 | |
| vineyard | 9 | 3.13 | 2.55 | |
| herbaceous vegetation | 10 | 17.84 | 19.76 | |
| agricultural land | 11 | 10.98 | 18.19 | |
| plowed land | 12 | 3.88 | 1.81 | |
| swimming pool | 13 | 0.01 | 0.02 | |
| snow | 14 | 0.15 | - | |
| clear cut | 15 | 0.15 | 0.82 | |
| mixed | 16 | 0.05 | 0.12 | |
| ligneous | 17 | 0.01 | - | |
| greenhouse | 18 | 0.12 | 0.15 | |
| other | 19 | 0.14 | 0.04 |
▶️ Modèle de référence (baseline): U-T&T (cliquer pour agrandir)
Nous proposons le modèle U-T&T, une architecture à deux branches qui combine les informations spatiales et temporelles à partir d'images aériennes très haute résolution et d'images satellites haute résolution en une seule sortie. L'architecture U-Net est utilisée pour la branche spatiale/texture, en utilisant un modèle avec un encodeur ResNet34 pré-entraîné sur ImageNet. Pour la branche spatio-temporelle, l'architecture U-TAE intègre un Encodeur à Attention Temporelle (TAE) pour explorer les caractéristiques spatiales et temporelles des séries temporelles de Sentinel-2, en appliquant des masques d'attention à différentes résolutions lors du décodage. Ce modèle permet la fusion des informations apprises à partir des deux sources.
▶️ Téléchargement du dataset (cliquer pour agrandir)
Pour l'instant sur inscription au défi !
| Données | Volume | Type | Lien |
|---|---|---|---|
| Images aériennes - entraînement | 50.7 Go | .zip | - |
| Images aériennes - test | 13.4 Go | .zip | - |
| Images Sentinel-2 - entraînement | 22.8 Go | .zip | - |
| Images Sentinel-2 - test | 6 Go | .zip | - |
| Annotations - entraînement | 485 Mo | .zip | - |
| Annotations - test | 108 Mo | .zip | - |
| Métadonnées aériennes | 16.1 Mo | .json | - |
| Correspondance images aériennes <-> Sentinel-2 | 16.1 Mo | .json | - |
| Shapefile zones | 392 Ko | .gpkg | - |
| Jeu de données exemple (entraînement et test réduits) | 1.6 Go/td> | .zip | download |
Citation
Si vous utilisez des données de FLAIR #2, merci d'inclure la citation suivante:
Texte brut:
Anatol Garioud, Nicolas Gonthier, Loic Landrieu, Apolline De Wit, Marion Valette, Marc Poupée, Sébastien Giordano and Boris Wattrelos. 2023.
FLAIR: a Country-Scale Land Cover Semantic Segmentation Dataset From Multi-Source Optical Imagery. (2023).
DOI: https://doi.org/10.48550/arXiv.2310.13336
BibTex:
@inproceedings{ign2023flair2,
title={FLAIR: a Country-Scale Land Cover Semantic Segmentation Dataset From Multi-Source Optical Imagery},
author={Anatol Garioud and Nicolas Gonthier and Loic Landrieu and Apolline De Wit and Marion Valette and Marc Poupée and Sébastien Giordano and Boris Wattrelos},
year={2023},
booktitle={Advances in Neural Information Processing Systems (NeurIPS) 2023},
doi={https://doi.org/10.48550/arXiv.2310.13336},
}