FLAIR
Artificial Intelligence challenges organised around geo-data and deep learning
Project maintained by IGNF

FLAIR #1 : semantic segmentation and domain adaptation 🌍🌱🏠🌳➡️🛩️
Challenge organized by IGN with the support of the SFPT.
The challenge took place on Codalab from November, 21st 2022 to March, 21st 2023. See the results here.
FLAIR #1 datapaper 📑 : https://arxiv.org/pdf/2211.12979.pdf
FLAIR #1 repository 📁 : https://github.com/IGNF/FLAIR-1
Pre-trained models ⚡ : https://huggingface.co/collections/IGNF/flair1-models-landcover-semantic-segmentation-65bb67415a5dbabc819a95de
▶️ Dataset description (click to expand)
We present here a large dataset ( >20 billion pixels) of aerial imagery, topographic information and land cover (buildings, water, forest, agriculture...) annotations with the aim to further advance research on semantic segmentation , domain adaptation and transfer learning. Countrywide remote sensing aerial imagery is by necessity acquired at different times and dates and under different conditions. Likewise, at large scales, the characteristics of semantic classes can vary depending on location and become heterogenous. This opens up challenges for the spatial and temporal generalization of deep learning models!
The FLAIR-one dataset consists of 77,412 high resolution patches (512x512 at 0.2 m spatial resolution) with 19 semantic classes. For this challenge and the associated baselines, due to imbalanced class frequencies, the number of classes has been reduced to 13 (remapping >12 to 13, see the datapaper for explanation).
| Class | Value | Freq.-train (%) | Freq.-test (%) | |
|---|---|---|---|---|
| building | 1 | 8.14 | 8.6 | |
| pervious surface | 2 | 8.25 | 7.34 | |
| impervious surface | 3 | 13.72 | 14.98 | |
| bare soil | 4 | 3.47 | 4.36 | |
| water | 5 | 4.88 | 5.98 | |
| coniferous | 6 | 2.74 | 2.39 | |
| deciduous | 7 | 15.38 | 13.91 | |
| brushwood | 8 | 6.95 | 6.91 | |
| vineyard | 9 | 3.13 | 3.87 | |
| herbaceous vegetation | 10 | 17.84 | 22.17 | |
| agricultural land | 11 | 10.98 | 6.95 | |
| plowed land | 12 | 3.88 | 2.25 | |
| swimming pool | 13 | 0.03 | 0.04 | |
| snow | 14 | 0.15 | - | |
| clear cut | 15 | 0.15 | 0.01 | |
| mixed | 16 | 0.05 | - | |
| ligneous | 17 | 0.01 | 0.03 | |
| greenhouse | 18 | 0.12 | 0.2 | |
| other | 19 | 0.14 | - |
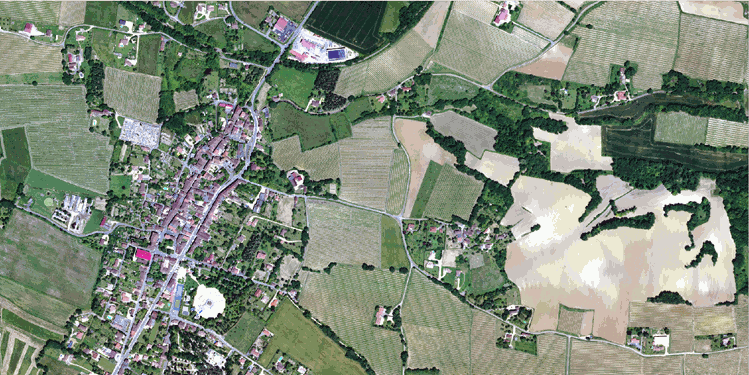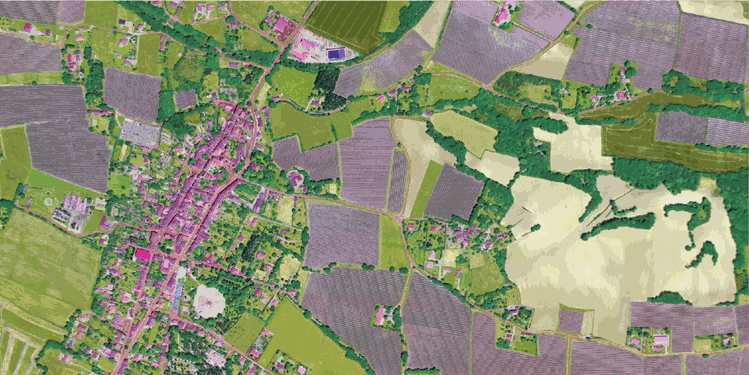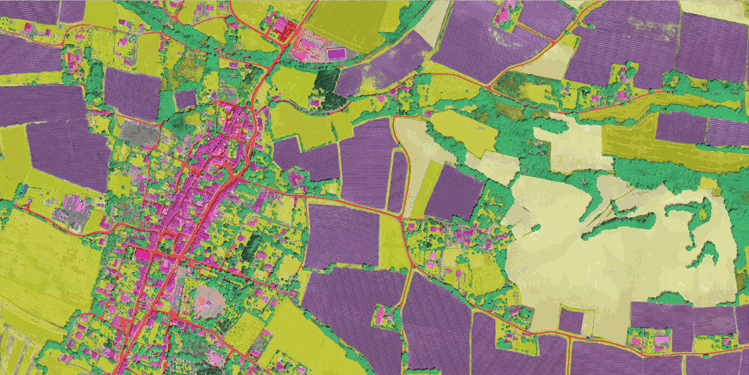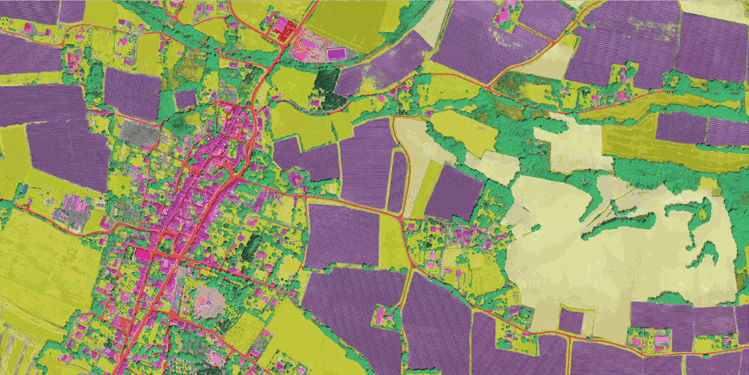
The dataset covers a total of approximatly 812 km², with patches that have been sampled accross the entire metropolitan French territory to be illustrating the different climate and landscapes (spatial domains). The aerial images included in the dataset were acquired during different months and years (temporal domains).
 |
 |
| Aerial image ORHTO HR® | Labels |
The test dataset consists of 15,700 patches from 10 domains not included in the train dataset. Class frequency and temporal domains of the test dataset includes a shift from the train dataset allowing to assess the domain adaptation capabilities of developped approaches.
▶️ Baseline model: U-Net (click to expand)
A U-Net architecture with a pre-trained ResNet34 encoder from the pytorch segmentation models library has been used for the baselines. The used architecture allows integration of patch-wise metadata information and employs commonly used image data augmentation techniques. Codes are available in the FLAIR #1 repository.
▶️ Dowload the dataset (click to expand)
| Data | Size | Type | Link |
|---|---|---|---|
| Aerial images - train | 50.7 Go | .zip | download |
| Aerial images - test | 13.4 Go | .zip | download |
| Labels - train | 485 Mo | .zip | download |
| Labels - test | 124 Mo | .zip | download |
| Aerial metadata | 16.1 Mo | .json | download |
| Areas shapes | 392 Ko | .gpkg | download |
| Toy dataset (subset of train and test) | 215 Mo | .zip | download |
Alternatively, get the dataset from our HuggingFace Page.
Reference
Please include a citation to the following paper if you use the FLAIR #1 dataset:
Plain text:
Anatol Garioud, Stéphane Peillet, Eva Bookjans, Sébastien Giordano, and Boris Wattrelos. 2022.
FLAIR #1: semantic segmentation and domain adaptation dataset. (2022).
DOI:https://doi.org/10.13140/RG.2.2.30183.73128/1
BibTex:
@article{ign2022flair1,
doi = {10.13140/RG.2.2.30183.73128/1},
url = {https://arxiv.org/pdf/2211.12979.pdf},
author = {Garioud, Anatol and Peillet, Stéphane and Bookjans, Eva and Giordano, Sébastien and Wattrelos, Boris},
title = {FLAIR #1: semantic segmentation and domain adaptation dataset},
publisher = {arXiv},
year = {2022}
}